

What is web scraping?
Web scraping is the technique of automatically extracting data from websites through programs or other sites. It is also known as "data scraping" or "web data harvesting." It is a widely used tool in digital transformation strategies and for automating the collection of public data.
How to implement with Node.js?
To perform web scraping in Node.js, you can use the Cheerio library, which utilizes some jQuery patterns for DOM manipulation. Its installation is quite simple: just run the following command:
npm i cheerioAfter the installation, you can start using the library by importing it as follows:
import * as cheerio from 'cheerio';In the example that will be presented, a project was created in Next.js in which, on the front end, there is an input waiting for the user to search for a word, triggering a request to the project's back end. On the back end, the Next.js API Routes functionality — which runs in Node.js — is used, and in this route, we will scrape data from two different dictionary sources.
Analysis of the HTML of each page
Before implementing, it's necessary to identify which data will be extracted and how it can be selected. In the example below, the word "dicionário" was searched on one of the sources that will be responsible for returning the definition of the word.
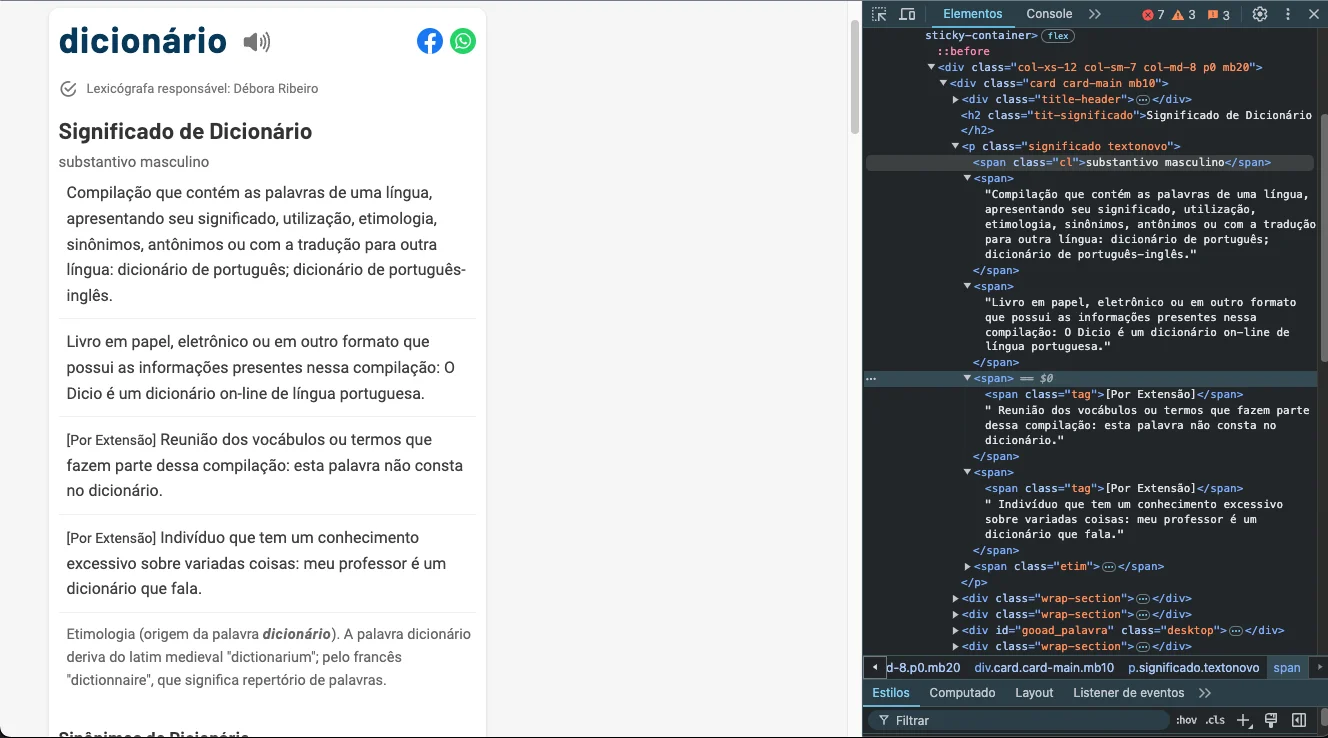
In the image above, you can see that the meanings are inside a "p" tag with the class "significado," and the children of this tag are of the "span" type, with a variation between the meaning and the classification of the meaning. This difference can be identified if the "span" tag has the "cl" class.
Therefore, an algorithm will be needed to access this "p" tag with the "significado" class, iterate through all the "span" tags, and differentiate those with the "cl" class from the others.
Next, the HTML from another dictionary site, which will be responsible for returning all related words to the searched word, will be displayed.
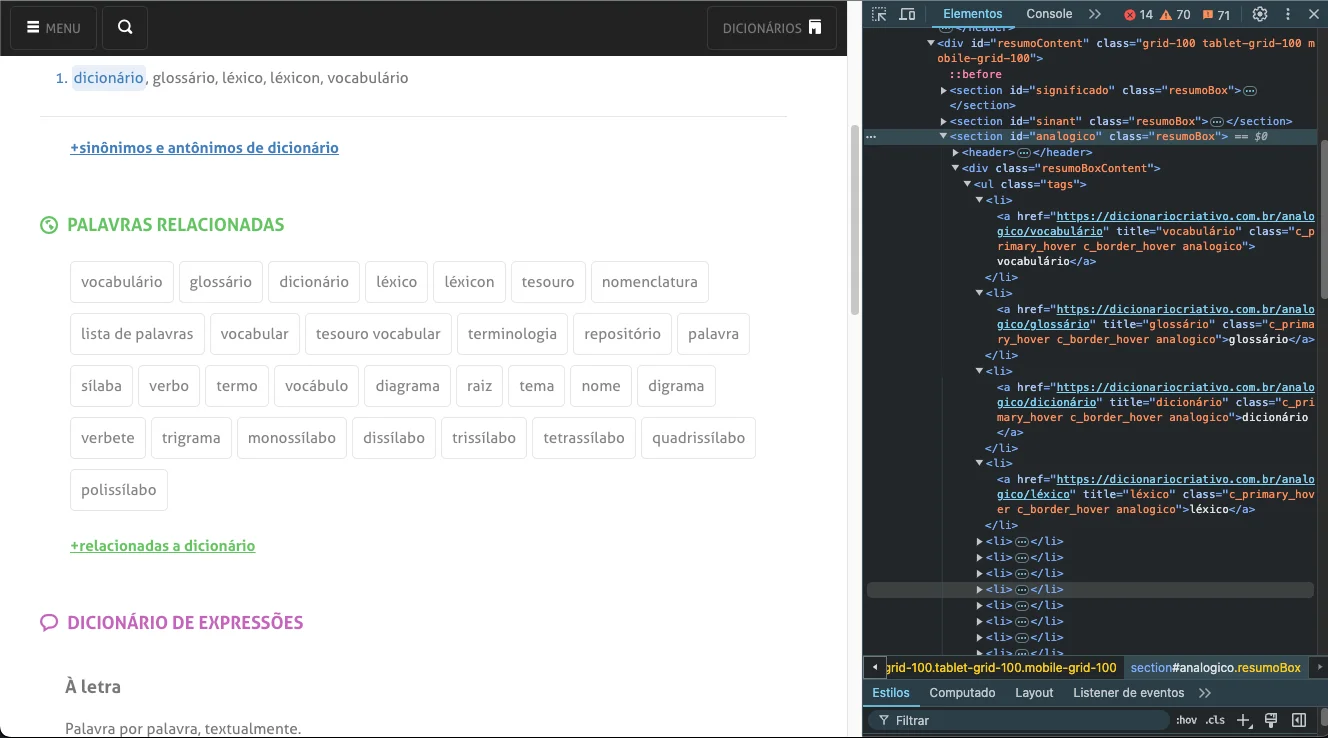
In the image above, you can observe that the related words are inside an unordered list structure ("ul" tag), and the parent tag is a "section" type with the id "analogico." With this, it will be necessary to create an algorithm that iterates through this unordered list and extracts the text from each element.
The implementation
Now that we have the analysis of each page and know how to extract its content, a step-by-step of this implementation will be presented.
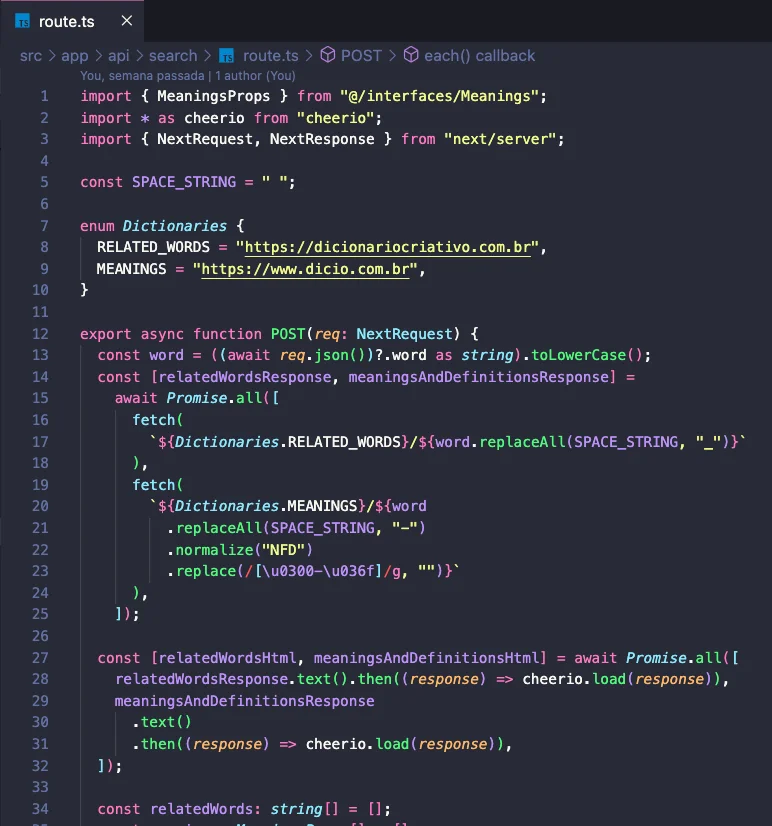
- In line 13, the searched word is processed;
- In line 14, the request is made to each dictionary, applying different processing to the searched word according to each site's format;
- In line 27, the DOM returned from each page is loaded into the Cheerio library.
After this first part, we have the constants that can be manipulated to obtain the desired data. Below is the continuation of this route.
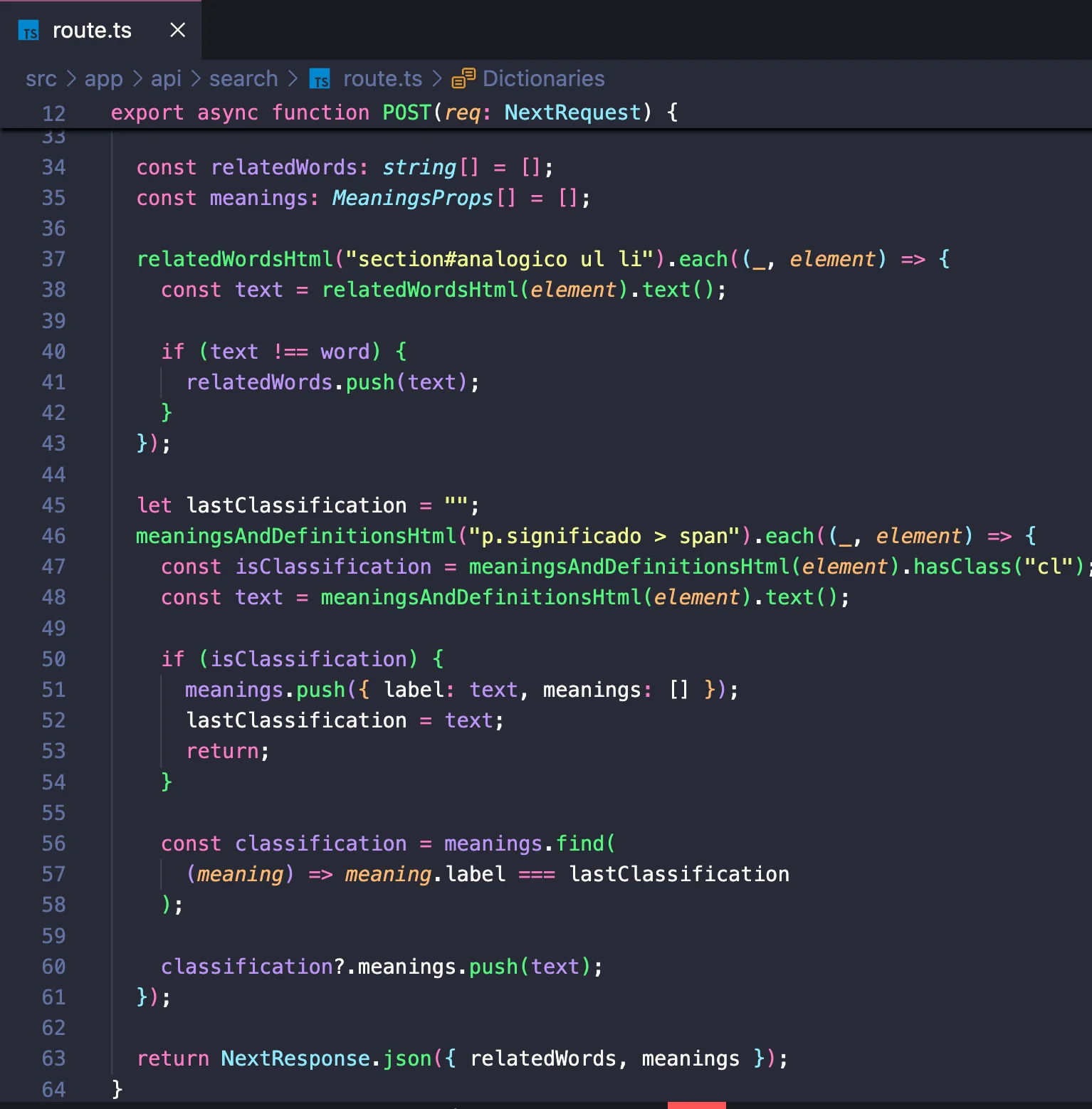
- In lines 37 to 43, an iteration is made over the elements of the dictionary responsible for returning the related words. If this word is different from the searched word, it is added to the array that will be returned in the response of this route.
- In lines 46 to 58, an iteration is made over the elements of the dictionary responsible for returning the meaning of the searched word. This function is more complex because this dictionary page not only returns the meanings of the word but also the "classification" of each meaning. Therefore, logic is required to check, through the class of each element, whether it is a classification or the meaning itself.
- In line 63, we have the end of this route, returning the variables that were manipulated throughout the function. Note: If the word does not exist, it will not be possible to iterate over the elements, and at the end of the route, the variables will return as empty arrays by default.
After executing and receiving the response from this route, the following result is generated on the front end:

Helpful links
- Published site link: https://dicionario-pt-br-sigma.vercel.app/
- Repository link: https://github.com/bretzke/web-scraping-dictionary
Conclusion
In this article, we discussed the definition of web scraping and a practical example in Node.js using the Cheerio library, which has a syntax similar to jQuery. Through its use, it was possible to render the definitions and related words for a searched word.
Of course, this was just a merely illustrative example, but in practice, we can use web scraping for many other purposes, such as: price monitoring on e-commerce sites, brand monitoring on the internet, market analysis in the financial sector, monitoring interest rates and currency quotes, among others.